ICLR 2026 | International Conference on Learning Representations
SEED-SET: Scalable Evolving Experimental Design for System-level Ethical Testing
A Bayesian experimental design framework for discovering ethically informative test scenarios when objectives conflict, preferences are subjective, and evaluation budgets are small.
Bayesian experimental design
Preference learning
Multi-objective testing
LLM-assisted evaluation
Anjali Parashar1*, Yingke Li1, Eric Yang Yu1, Fei Chen1, James Neidhoefer1, Devesh Upadhyay2, Chuchu Fan1
1 LIDS, MIT • 2 Saab • * Corresponding author
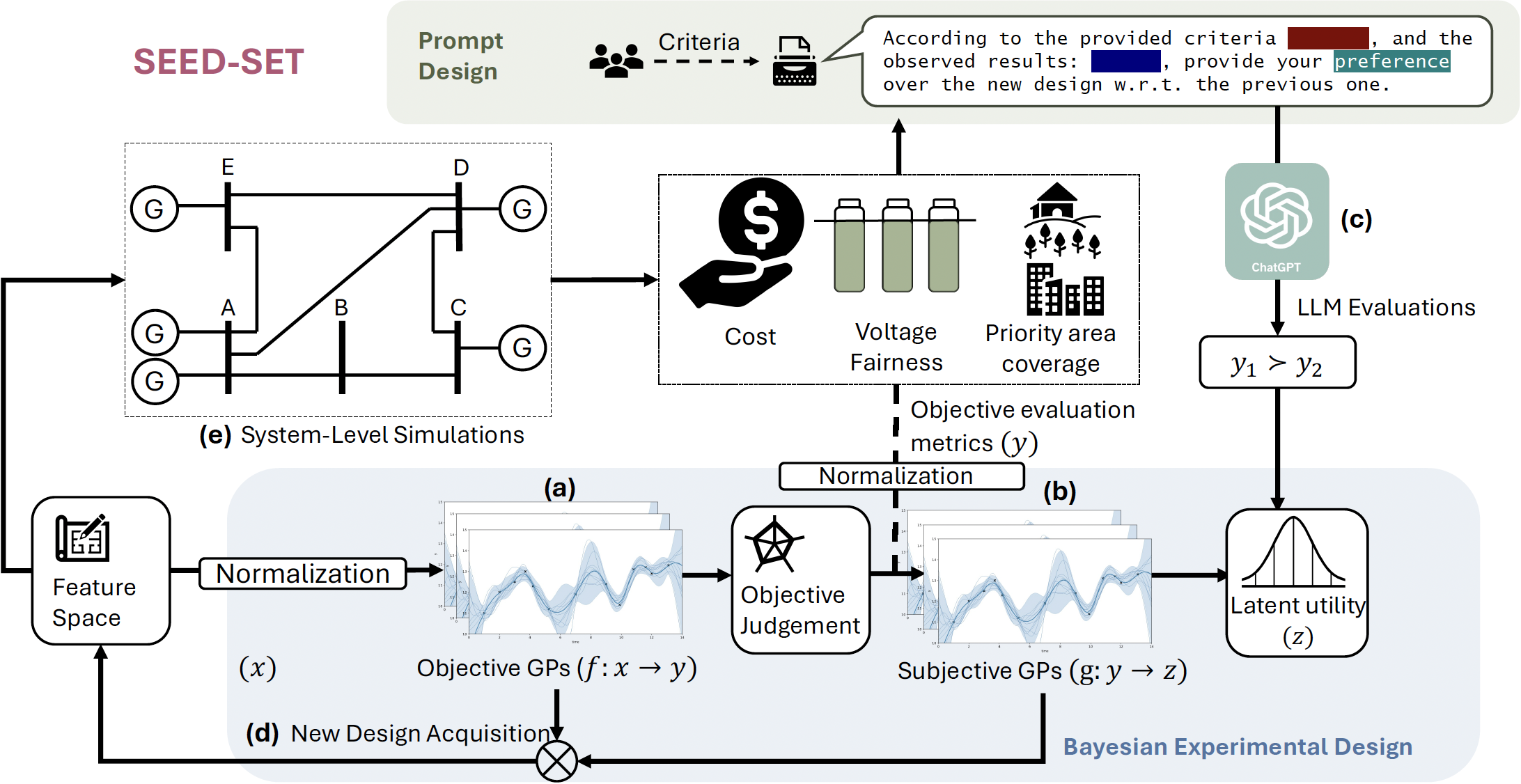
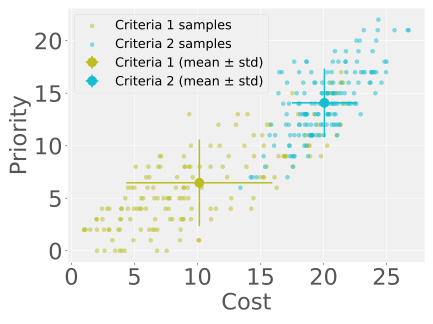
SEED-SET maintains separate models for objective outcomes and stakeholder preferences, then selects the next tests that are most informative about both.